
From: https://www.math3ma.com/blog/matrices-probability-graphs
Today I’d like to share an idea. It’s a very simple idea. It’s not fancy and it’s certainly not new. In fact, I’m sure many of you have thought about it already. But if you haven’t—and even if you have!—I hope you’ll take a few minutes to enjoy it with me. Here’s the idea:
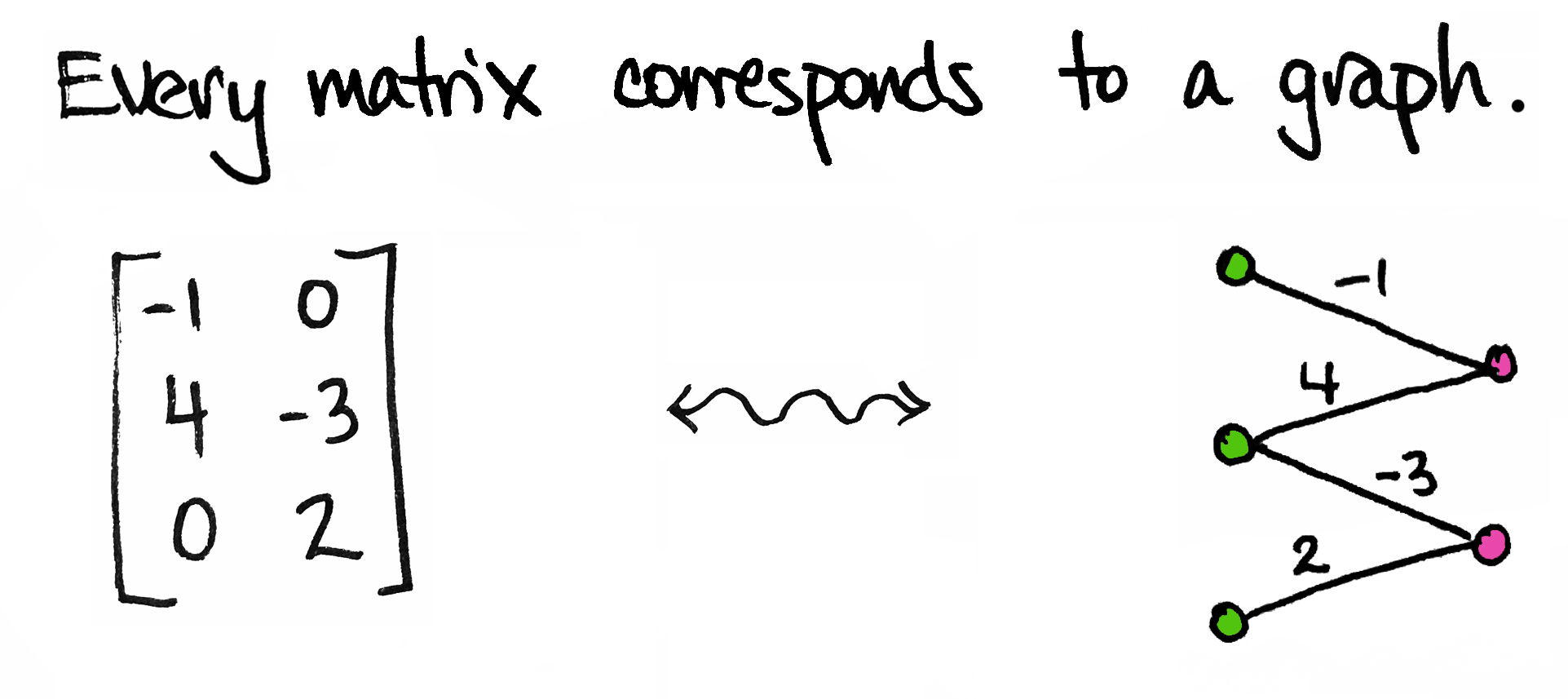
So simple! But we can get a lot of mileage out of it.
To start, I’ll be a little more precise: every matrix corresponds to a weighted bipartite graph. By “graph” I mean a collection of vertices (dots) and edges; by “bipartite” I mean that the dots come in two different types/colors; by “weighted” I mean each edge is labeled with a number.
The graph above corresponds to a 3×23×2 matrix MM. You’ll notice I’ve drawn three greengreen dots—one for each row of MM—and two pinkpink dots—one for each column of MM. I’ve also drawn an edge between a green dot and a pink dot if the corresponding entry in MM is non-zero.

For example, there’s an edge between the second green dot and the first pink dot because M21=4M21=4, the entry in the second row, first column of MM, is not zero. Moreover, I’ve labeled that edge by that non-zero number. On the other hand, there is no edge between the first green dot and the second pink dot because M12M12, the entry in the first row, second column of the matrix, is zero.
Allow me to describe the general set-up a little more explicitly.
Any matrix MM is an array of n×mn×m numbers. That’s old news, of course. But such an array can also be viewed as a function M:X×Y→RM:X×Y→R where X={x1,…,xn}X={x1,…,xn} is a set of nn elements and Y={y1,…,ym}Y={y1,…,ym} is a set of mmelements. Indeed, if I want to describe the matrix MM to you, then I need to tell you what each of its ijijth entries are. In other words, for each pair of indices (i,j)(i,j), I need to give you a real number MijMij. But that’s precisely what a function does! A function M:X×Y→RM:X×Y→R associates for every pair (xi,yj)(xi,yj) (if you like, just drop the letters and think of this as (i,j)(i,j)) a real number M(xi,yj)M(xi,yj). So simply write MijMij for M(xi,yj)M(xi,yj).
Et voila. A matrix is a function.

As suggested, let’s further think of XX’s elements as being greengreen and YY’s elements as being pinkpink. Then a matrix MMcorresponds to a weighted bipartite graph in the following way: the vertices of the graph have two different colors provided by XX and YY, and there is an edge between every xixi and yjyj which is labeled by the number MijMij. But if this number is zero, then simply omit that edge.
Et voila. Every matrix corresponds to a graph.
Nice things happen when we visualize matrices in this way. For instance…
Matrix multiplication corresponds to traveling along paths.
Given two matrices (graphs) M:X×Y→RM:X×Y→R and N:Y×Z→RN:Y×Z→R, we can multiply them by sticking their graphs together and traveling along paths: the ijijth entry of MNMN, i.e. the value of the edge connecting xixi to zjzj, is obtained by multiplying the edges along each path from xixi to zjzj and adding them together. For example:

Symmetric matrices correspond to symmetric graphs.
A matrix is symmetric if it is equal to its transpose. That symmetry is always seen by reflecting across the diagonal of the matrix. But you can also see the symmetry in the graph. In particular, the graph makes it visually intuitive why MM⊤MM⊤ and M⊤MM⊤M are always symmetric, for any MM!

Matrices with all nonzero entries correspond to complete bipartite graphs.
If none of the entries of a matrix is zero, then there are no missing edges in its corresponding graph. That means every vertex in XX is connected to every vertex in YY. Such bipartite graphs are called complete.

Block matrices correspond to disconnected graphs.
More specifically, the block matrix obtained from a direct sum corresponds to a disconnected graph. The direct sum of two matrices is obtained by stacking them together into one larger array. (Not unlike the direct sum of vectors.) The result is a big block matrix with zero-blocks. The graph of that matrix is obtained by stacking the graphs of the original matrices together.

We could say more about matrices and graphs, but I’d like to steer the conversation in a slightly different direction. As it turns out, probability fits in very nicely with our matrix-graph discussion. It does so by way of another nice little fact:

For example:

The graphs of such probability distributions allow us to read off some nice things.
Joint Probability
By construction, the edges of the graph capture the joint probabilities: the probability of (xi,yj)(xi,yj) is the label on the edge connecting them.

Marginal Probability
Marginal probabilities are obtained by summing along the rows/columns of the matrix (equivalently, of the chart above). For example, the probability of x1x1 is p(x1)=p(x1,y1)+p(x1,y2)=18+0p(x1)=p(x1,y1)+p(x1,y2)=18+0, which is the sum of the first row. Likewise, the probability of y2y2 is p(y2)=p(x1,y2)+p(x2,y2)+p(x3,y2)=0+18+14p(y2)=p(x1,y2)+p(x2,y2)+p(x3,y2)=0+18+14, which is the sum of the second column.
In the graph, the marginal probability of xixi is the sum of all edges that have xixi as a vertex. Similarly, the marginal probability of yjyj is the sum of all edges that have yjyj as a vertex.

Conditional Probability
Conditional probabilities are obtained by dividing a joint probability by a marginal probability. For example, the probability of x3x3 given y2y2 is p(x3|y2)=p(x3,y2)p(y2)p(x3|y2)=p(x3,y2)p(y2). In the graph, this is seen by dividing the edge joining x3x3 and y2y2 by the sum of all edges incident to y2y2. Likewise, the conditional probability of some yiyi given xjxj is the value of the edge joining the two, divided by the sum of all edges incident to xjxj.

Pretty simple, right?
There’s nothing sophisticated here, but sometimes it’s nice to see old ideas in new ways!

Relations as Matrices
I’ll close this post with an addendum—another simple fact that I think is really delightful, namely: matrix arithmetic makes sense over commutative rings. Not just fields like RR or CC. In fact, it gets better. You don’t even need negatives to multiply matrices: matrix arithmetic makes sense over commutative semi-rings! (A semi-ring is a ring without additive inverses.)
I think this is so delightful because the set with two elements Z2={0,1}Z2={0,1} forms a semi-ring with the following addition and multiplication operations:

Why is this so great? Because a matrix M:X×Y→Z2M:X×Y→Z2 is the same thing as a relation. A relation is just the name for a subset RR of a Cartesian product X×YX×Y. In other words, every Z2Z2-valued matrix defines a relation, and every relation defines a Z2Z2-valued matrix: Mij=1Mij=1 if and only if the pair (xi,yj)(xi,yj) is an element of the subset RR, and Mij=0Mij=0 otherwise.

The graphs of matrices valued in Z2Z2 are exactly like the graphs discussed above, except now the weight of any edge is either 0 or 1. If the weight is 0 then, as before, we simply won’t draw that edge.
(By the way, you can now ask, “Since every relation corresponds to a matrix in Z2Z2, what do matrices corresponding to equivalence relations look like?” But I digress….)
By changing the underlying (semi)ring from RR to Z2Z2, we’ve changed the way we interpret the weights. For instance, in the probabilistic scenario above, we could’ve asked, “What’s the probability of getting from x1x1 to y1y1?” The answer is provided by the weight on the corresponding edge, in that case: 12.5%. Alternatively, when the matrix is valued in Z2Z2, the question changes to: “Is it possible to get from x1x1 to y1y1?” The answer is Yes if the edge is labeled by 1, and it’s No if the edge is labeled by 0. (This nice idea has been explained in various places, like here for instance.)
What’s great is that composition of relations is exactly matrix multiplication using the Z2Z2 arithmetic above. In other words, given any two relations R⊂X×YR⊂X×Y and S⊂Y×ZS⊂Y×Z, there is a new relation SR⊂X×ZSR⊂X×Zconsisting of all pairs (x,z)(x,z) such that there exists at least one y∈Yy∈Y with (x,y)∈R(x,y)∈R and (y,z)∈S(y,z)∈S. This new relation is exactly that specified by the product of the matrices representing RR and SS.

This little fact about matrices/relations is definitely at the top of my list of favorite-math-facts.* One reason is because the category of finite sets and relations is a lot like the category of finite vector spaces and linear maps. Actually, it’s more like the category of finite-dimensional Hilbert spaces. And that means that a lot of seemingly disparate ideas all of the sudden become closely related. The connections can be made more precise, and it’s a story that’s often shared in the category theory community. Hopefully I’ll get around to sharing it here on the blog, too.
*Relations are often under-appreciated, I think. In high school, I learned that functions are of utmost importance. “Assignments must only have one output for each input,” they said. No one ever mentioned anything about multiple outputs. Whenever such an anomaly did crop up, it was usually presented as abnormal and off-limits. But relations deserve much better treatment! One reason is because relations are to sets what linear maps are to vector spaces. There’s a lot of juice in linear algebra, so there’s a lot of juice in relations too. In short, relations are very much top-notch citizens.
